
On word analogies and negative results in NLP
In real world, fake news spread faster than facts. People’s attention is caught by sensational, exaggerated, clickbait-y messages like “5.23 million more immigrants are moving to the UK”. Any subsequent fact-checking messages look less sensational and they will not reach as many people. Once the damage is done, it’s done.
Thank God this never happens in academia. Right?
Wrong.
Experts are as susceptible as the rest of the populace - see for example Daniel Kahneman’s account of an author of a statistics textbook who readily went with stereotype rather than provided base rate information (Kahneman, 2013). Maybe we - researchers - have it even worse, because we also have to publish-or-perish. The publication treadmill demands eye-catching, breakthrough results that can’t possibly be produced at the required speed. We rarely have the problem of people deliberately faking results, but… how shall I put it… there isn’t exactly an incentive to triple-check things before they land on Arxiv. If you happen to be right, you get to be the first to publish that, and if you’re wrong - no shame in it, you can always revise.
The readers are not necessarily triple-checking either. For an academic publication it would require much more than a google search, so we rarely bother unless we’re reviewing or replicating. The worst case scenario is when the shiny but hasty result also conforms to your own intuitions about how things should work - i.e. when you’re told something you want to believe anyway.
I think this is what happened to word analogies (Mikolov, Chen, Corrado, & Dean, 2013). Its over 11K citations are mostly due to the hugely popular word2vec architecture, but the idea of word analogies rode the same wave. A separate paper on “linguistic regularities” (Mikolov, Yih, & Zweig, 2013) currently has extra 2K citations.
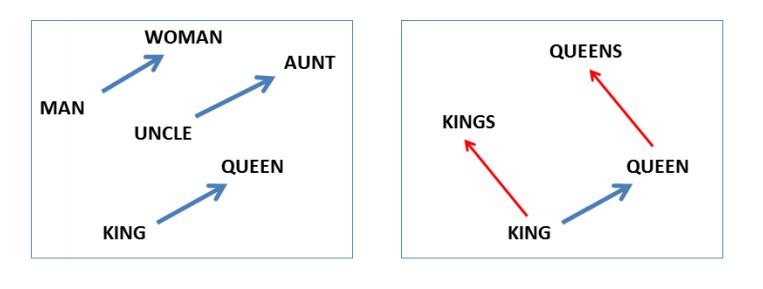
These citations are not just something from 2013 either. Because it’s so tempting to believe that language really works this way, the word analogies are still everywhere. Only in June 2019, I heard them mentioned in the first 10 minutes of a NAACL invited talk, in a word embeddings lecture in the CISS dialogue summer school, and all over Twitter. It just soo makes sense that language relations are all neat and regular like this:
However, that may be too good to be true.
All things wrong with word analogies.
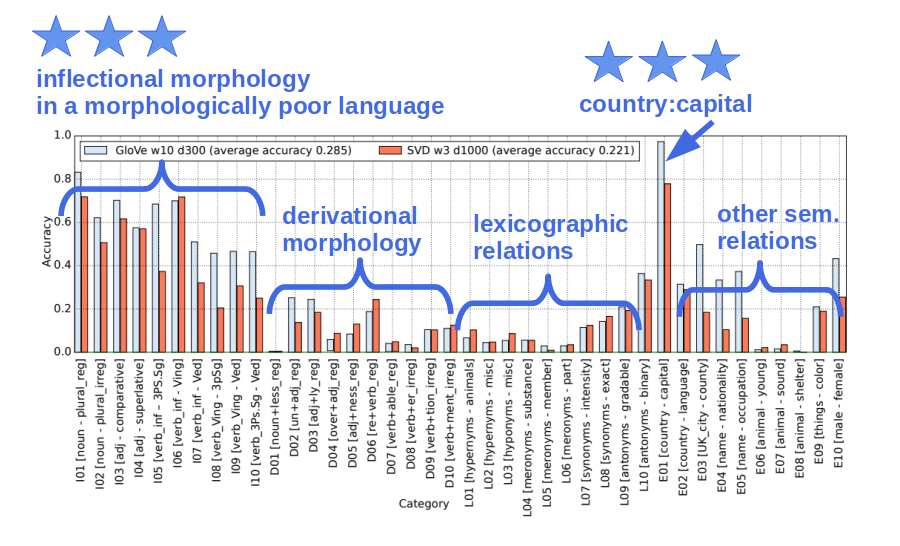
To the best of my knowledge, the first suspicions about vector offset arose when it didn’t work for lexicographic relations (Köper, Scheible, & im Walde, 2015) - a pattern later confirmed by (Karpinska, Li, Rogers, & Drozd, 2018). Then the BATS dataset (Gladkova, Drozd, & Matsuoka, 2016) offered a larger balanced sample of 40 relations, among which the vector offset worked well only on those that happened to be included in the original Google dataset.
So why doesn’t it generalize, if language relations are so neat and regular? Well, it turns out that it wouldn’t have worked in the first place if the 3 source words were not excluded from the set of possible answers. In the original formulation, the solution to \(king-man+woman\) should be \(queen\), given that the vectors \(king\), \(man\) and \(woman\) are excluded from the set of possible answers. Tal Linzen showed that for some relations you get considerable accuracy by simply getting the nearest neighbor of \(woman\) word, or the one most similar to both \(woman\) and \(king\) (without \(man\)) (Linzen, 2016). And here’s what happens if you don’t exclude any of them (Rogers, Drozd, & Li, 2017):

If in most cases the predicted vector is the closest to the source \(woman\) vector, it means that the vector offset is simply too small to induce a meaning shift on its own. And that means that adding it will not get you somewhere significantly different. Which means you’re staying in the neighborhood of the original vectors.
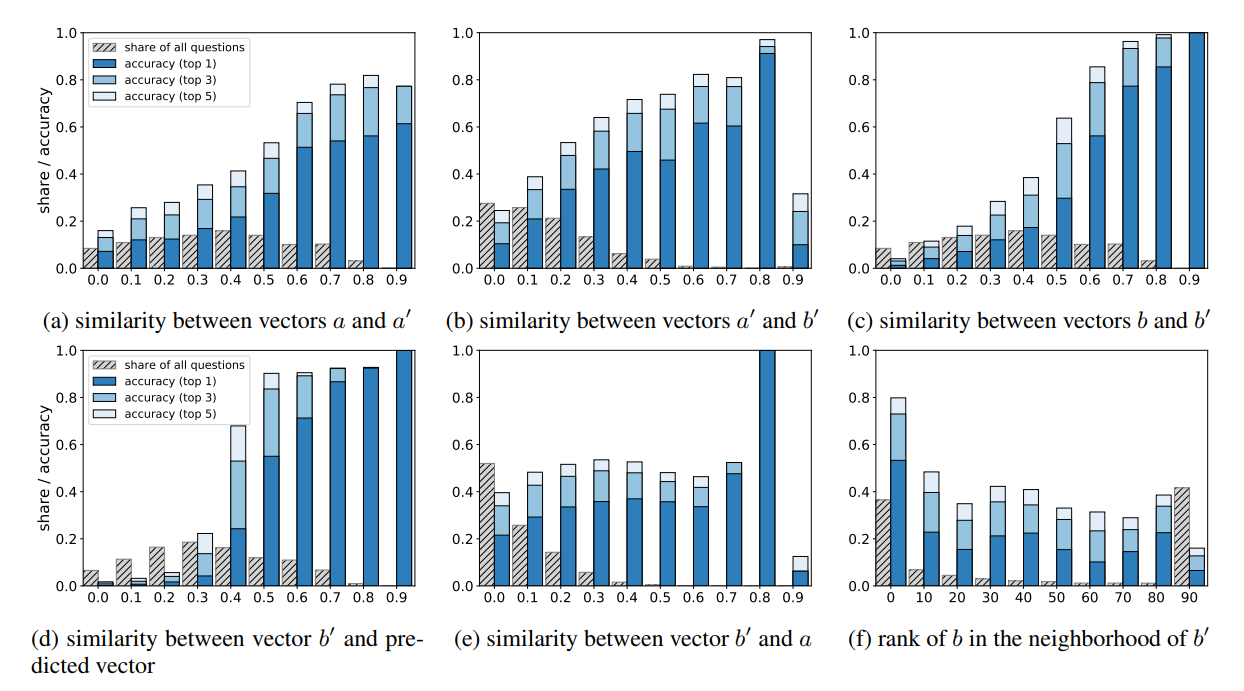
Here are some more experiments showing that if the source vectors \(a\) (“man”), \(a'\) (king), and \(b\) (“woman”) are excluded, your likelihood to succeed depends on how close the correct answer is to the source words (Rogers, Drozd, & Li, 2017):
One could object that this is due to bad word embeddings, and ideal embeddings would have every possible relation encoded so that it would be recoverable from vector offset. That remains to be shown empirically, but from theoretical perspective it is not likely to happen:
- Semantically, the idea of manipulating vector differences is reminiscent of componential analysis of the 1950s, and there are good reasons why that is no longer actively developed. For example, does “man” + “unmarried” as definition of “bachelor” apply to Pope?
- Distributionally, even seemingly perfect analogy between cat:cats and table:tables are never perfect. For example, turn the tables is not the same as turn the table, they will appear in different contexts - but that difference does not apply to cat:cats. Given hundreds of such differences, why would we expect the aggregate representations to always perfectly line up? And if they did, would that even be a good representation of language semantics? If we are to ever have good language generation, we need to be able to take into account such nuances, not to discard them.
To sum up: several research papers brought up good reasons to doubt the efficacy of vector offset. If the formulation of vector offset excludes the source vectors, it will appear to work for the small original dataset, where much of its success can be attributed to basic cosine similarity. But it will fail to generalize to a larger set of linguistic relations.
(Lack of) impact on further research
The focus of this post is not just the above negative evidence about vector offset, but the fact that these multiple reports of negative results never reached the same audience of thousands of researchers who were impressed by the original Mikolov’s paper.
Obviously, I’m impartial here because some of this work is mine, but isn’t it just counter-productive for the field in general? If there are serious updates to a widely cited but too-good-to-be-true paper, it is in everybody’s interest for those updates to travel fast. They could save people the effort of either doing the same work again, or the wasted effort of building on the original untested assumption. Right?
Well, the problem with publishing negative results is well-known, and perhaps it’s not coincidental that only one of the above papers even made it to one of the main conferences. However, there are now two ACL, one COLING, and one best-paper-mention ICML paper that provide mathematical proofs for why the vector offset should work (Gittens, Achlioptas, & Mahoney, 2017; Hakami, Hayashi, & Bollegala, 2018; Ethayarajh, Duvenaud, & Hirst, 2019; Allen & Hospedales, 2019). Go figure. Only one paper also took a mathematical perspective, but bravely arrived at the opposite conclusion (Schluter, 2018).
Obviously, these positions need to be reconciled in the future. I am fully open to the possibility that the vector offset does indeed work, and the above negative evidence is somehow wrong. That would actually be great for everybody, as it would mean that we already have an intuitive, cheap, and reliable way to perform analogical reasoning. But that still needs to be shown, and so far the papers providing proofs for vector offset did not address the available negative evidence.
Consider that if the negative evidence is correct, this has serious implications for the field. It would mean that we are pursuing a simplistic model of linguistic relations that is not representative of most of language. For instance, the vector offset attracted the attention of researchers on fairness/bias, and many practitioners actually use it in earnest. Here’s a NIPS paper that started from accepting that the underlying vector offset mechanism works: (Bolukbasi, Chang, Zou, Saligrama, & Kalai, 2016). But this one didn’t: (Nissim, van Noord, & van der Goot, 2019). Let me quote the authors on what it would mean to make social conclusions on the basis of unreliable metrics:

To conclude: analogical reasoning is an incredibly important aspect of human reasoning, and we have to get it right if we’re ever to arrive at general AI. So far, from what I’ve seen, linear vector offsets in word embeddings are not the right way to think of it. But there are plenty of other directions, including better methods for analogical reasoning (Drozd, Gladkova, & Matsuoka, 2016; Vine, Geva, & Bruza, 2018; Bouraoui, Jameel, & Schockaert, 2018; Dufter & Schütze, 2019) and specialized representations for analogous pairs (Washio & Kato, 2018; Joshi, Choi, Levy, Weld, & Zettlemoyer, 2018; Hakami & Bollegala, 2019; Camacho-Collados, Espinosa-Anke, & Schockaert, 2019). If we’re not married to the ideal of natural language with impossibly regular relations, shouldn’t we try to maximize the research effort in more promising directions?
How we can encourage fact-checking of widespread claims
The problem with vector offset is not unique. Its components are (1) a shiny result that is intuitively appealing and becomes too-famous-to-be-questioned, (2) the low visibility of negative results, even when they are available. In NLP, the latter problem is aggravated by the insane Arxiv pace. When you work on “a truth universally accepted”, and you can’t even keep up with the list of papers that you want to read, why would you bother searching for papers nobody cited?
It is admittedly hard to make negative results sexy, but in high-profile cases I think it is doable. Why don’t we have an impactful-negative-result award category at ACL conferences, to encourage fact-checking of at least the most widely-accepted assumptions? This would:
- increase the awareness of widespread problems, so that people do not build on shaky assumptions;
- identify high-profile research directions where more hands are needed next year, thus stimulating the overall progress in NLP;
- help with reproducibility crisis by encouraging replication studies and reporting of negative results.
For example, in NAACL 2019 there were several interesting papers that could definitely be considered for such an award. A few personal favorites:
- exposing the lack of transfer between QA datasets (Yatskar, 2019),
- limitations of attention as “explaining” mechanism (Jain & Wallace, 2019),
- multimodal QA systems that work better by simply ignoring some of the input modalities (Thomason, Gordon, & Bisk, 2019).
2 out of 3 of these great papers were posters, and I can not imagine how many more did not even make it through review. I would argue that it sends a message to the people doing this important work, and it is the wrong message.
On the other hand, imagine that such an award existed, and was granted, say, to (Yatskar, 2019). Then everybody in the final session got to hear about the lack of transfer between 3 popular QA datasets. QA is one of the most popular tasks, so wouldn’t it be good for the community to highlight the problem, so that next year more people focus on solving QA rather than particular datasets? Perhaps the impactful-negative-result paper could also be chosen so as to match next year’s theme.
***
References
- Allen, C., & Hospedales, T. (2019). Analogies Explained: Towards Understanding Word Embeddings. ArXiv:1901.09813 [Cs, Stat].
@article{AllenHospedales_2019_Analogies_Explained_Towards_Understanding_Word_Embeddings, archiveprefix = {arXiv}, eprinttype = {arxiv}, eprint = {1901.09813}, primaryclass = {cs, stat}, title = {Analogies {{Explained}}: {{Towards Understanding Word Embeddings}}}, shorttitle = {Analogies {{Explained}}}, journal = {arXiv:1901.09813 [cs, stat]}, url = {http://arxiv.org/abs/1901.09813}, author = {Allen, Carl and Hospedales, Timothy}, month = jan, year = {2019} } - Bolukbasi, T., Chang, K.-W., Zou, J., Saligrama, V., & Kalai, A. (2016). Man Is to Computer Programmer As Woman Is to Homemaker? Debiasing Word Embeddings. Proceedings of the 30th International Conference on Neural Information Processing Systems, 4356–4364. USA: Curran Associates Inc.
@inproceedings{BolukbasiChangEtAl_2016_Man_is_to_Computer_Programmer_As_Woman_is_to_Homemaker_Debiasing_Word_Embeddings, address = {{USA}}, series = {{{NIPS}}'16}, title = {Man Is to {{Computer Programmer As Woman}} Is to {{Homemaker}}? {{Debiasing Word Embeddings}}}, isbn = {978-1-5108-3881-9}, shorttitle = {Man Is to {{Computer Programmer As Woman}} Is to {{Homemaker}}?}, booktitle = {Proceedings of the 30th {{International Conference}} on {{Neural Information Processing Systems}}}, publisher = {{Curran Associates Inc.}}, url = {http://dl.acm.org/citation.cfm?id=3157382.3157584}, author = {Bolukbasi, Tolga and Chang, Kai-Wei and Zou, James and Saligrama, Venkatesh and Kalai, Adam}, year = {2016}, pages = {4356--4364} } - Bouraoui, Z., Jameel, S., & Schockaert, S. (2018). Relation Induction in Word Embeddings Revisited. Proceedings of the 27th International Conference on Computational Linguistics, 1627–1637.
@inproceedings{BouraouiJameelEtAl_2018_Relation_Induction_in_Word_Embeddings_Revisited, title = {Relation {{Induction}} in {{Word Embeddings Revisited}}}, language = {en-us}, booktitle = {Proceedings of the 27th {{International Conference}} on {{Computational Linguistics}}}, url = {https://www.aclweb.org/anthology/papers/C/C18/C18-1138/}, author = {Bouraoui, Zied and Jameel, Shoaib and Schockaert, Steven}, month = aug, year = {2018}, pages = {1627-1637} } - Drozd, A., Gladkova, A., & Matsuoka, S. (2016). Word Embeddings, Analogies, and Machine Learning: Beyond King - Man + Woman = Queen. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, 3519–3530. Osaka, Japan, December 11-17.
@inproceedings{DrozdGladkovaEtAl_2016_Word_embeddings_analogies_and_machine_learning_beyond_king_man_woman_queen, address = {{Osaka, Japan, December 11-17}}, title = {Word Embeddings, Analogies, and Machine Learning: Beyond King - Man + Woman = Queen}, shorttitle = {Word {{Embeddings}}, {{Analogies}}, and {{Machine Learning}}}, booktitle = {Proceedings of {{COLING}} 2016, the 26th {{International Conference}} on {{Computational Linguistics}}: {{Technical Papers}}}, url = {https://www.aclweb.org/anthology/C/C16/C16-1332.pdf}, author = {Drozd, Aleksandr and Gladkova, Anna and Matsuoka, Satoshi}, year = {2016}, keywords = {peer-reviewed}, pages = {3519--3530} } - Dufter, P., & Schütze, H. (2019). Analytical Methods for Interpretable Ultradense Word Embeddings. ArXiv:1904.08654 [Cs].
@article{DufterSchutze_2019_Analytical_Methods_for_Interpretable_Ultradense_Word_Embeddings, archiveprefix = {arXiv}, eprinttype = {arxiv}, eprint = {1904.08654}, primaryclass = {cs}, title = {Analytical {{Methods}} for {{Interpretable Ultradense Word Embeddings}}}, journal = {arXiv:1904.08654 [cs]}, url = {http://arxiv.org/abs/1904.08654}, author = {Dufter, Philipp and Sch{\"u}tze, Hinrich}, month = apr, year = {2019} } - Ethayarajh, K., Duvenaud, D., & Hirst, G. (2019). Towards Understanding Linear Word Analogies. To Appear in ACL 2019.
@article{EthayarajhDuvenaudEtAl_2019_Towards_Understanding_Linear_Word_Analogies, archiveprefix = {arXiv}, eprinttype = {arxiv}, eprint = {1810.04882}, title = {Towards {{Understanding Linear Word Analogies}}}, journal = {To appear in ACL 2019}, url = {http://arxiv.org/abs/1810.04882}, author = {Ethayarajh, Kawin and Duvenaud, David and Hirst, Graeme}, month = oct, year = {2019} } - Gittens, A., Achlioptas, D., & Mahoney, M. W. (2017). Skip-Gram - Zipf + Uniform = Vector Additivity. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 69–76. https://doi.org/10.18653/v1/P17-1007
@inproceedings{GittensAchlioptasEtAl_2017_SkipGram_Zipf_Uniform_Vector_Additivity, title = {Skip-{{Gram}} - {{Zipf}} + {{Uniform}} = {{Vector Additivity}}}, language = {en-us}, booktitle = {Proceedings of the 55th {{Annual Meeting}} of the {{Association}} for {{Computational Linguistics}} ({{Volume}} 1: {{Long Papers}})}, doi = {10.18653/v1/P17-1007}, url = {https://www.aclweb.org/anthology/papers/P/P17/P17-1007/}, author = {Gittens, Alex and Achlioptas, Dimitris and Mahoney, Michael W.}, month = jul, year = {2017}, pages = {69-76} } - Gladkova, A., Drozd, A., & Matsuoka, S. (2016). Analogy-Based Detection of Morphological and Semantic Relations with Word Embeddings: What Works and What Doesn’t. Proceedings of the NAACL-HLT SRW, 47–54. https://doi.org/10.18653/v1/N16-2002
@inproceedings{GladkovaDrozdEtAl_2016_Analogybased_detection_of_morphological_and_semantic_relations_with_word_embeddings_what_works_and_what_doesnt, address = {{San Diego, California, June 12-17, 2016}}, title = {Analogy-Based Detection of Morphological and Semantic Relations with Word Embeddings: What Works and What Doesn't.}, booktitle = {Proceedings of the {{NAACL}}-{{HLT SRW}}}, publisher = {{ACL}}, doi = {10.18653/v1/N16-2002}, url = {https://www.aclweb.org/anthology/N/N16/N16-2002.pdf}, author = {Gladkova, Anna and Drozd, Aleksandr and Matsuoka, Satoshi}, year = {2016}, keywords = {peer-reviewed}, pages = {47-54} } - Hakami, H., & Bollegala, D. (2019). Learning Relation Representations from Word Representations. AKBC 2019.
@inproceedings{HakamiBollegala_2019_Learning_Relation_Representations_from_Word_Representations, title = {Learning {{Relation Representations}} from {{Word Representations}}}, booktitle = {{{AKBC}} 2019}, url = {https://openreview.net/forum?id=r1e3WW5aTX\¬eId=BklR5HOySN}, author = {Hakami, Huda and Bollegala, Danushka}, year = {2019} } - Hakami, H., Hayashi, K., & Bollegala, D. (2018). Why Does PairDiff Work? - A Mathematical Analysis of Bilinear Relational Compositional Operators for Analogy Detection. Proceedings of the 27th International Conference on Computational Linguistics, 2493–2504.
@inproceedings{HakamiHayashiEtAl_2018_Why_does_PairDiff_work, title = {Why Does {{PairDiff}} Work? - {{A Mathematical Analysis}} of {{Bilinear Relational Compositional Operators}} for {{Analogy Detection}}}, shorttitle = {Why Does {{PairDiff}} Work?}, language = {en-us}, booktitle = {Proceedings of the 27th {{International Conference}} on {{Computational Linguistics}}}, url = {https://www.aclweb.org/anthology/papers/C/C18/C18-1211/}, author = {Hakami, Huda and Hayashi, Kohei and Bollegala, Danushka}, month = aug, year = {2018}, pages = {2493-2504} } - Jain, S., & Wallace, B. C. (2019). Attention Is Not Explanation. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 3543–3556.
@inproceedings{JainWallace_2019_Attention_is_not_Explanation, title = {Attention Is Not {{Explanation}}}, language = {en-us}, booktitle = {Proceedings of the 2019 {{Conference}} of the {{North American Chapter}} of the {{Association}} for {{Computational Linguistics}}: {{Human Language Technologies}}, {{Volume}} 1 ({{Long}} and {{Short Papers}})}, url = {https://aclweb.org/anthology/papers/N/N19/N19-1357/}, author = {Jain, Sarthak and Wallace, Byron C.}, month = jun, year = {2019}, pages = {3543-3556} } - Joshi, M., Choi, E., Levy, O., Weld, D. S., & Zettlemoyer, L. (2018). Pair2vec: Compositional Word-Pair Embeddings for Cross-Sentence Inference. ArXiv:1810.08854 [Cs].
@article{JoshiChoiEtAl_2018_pair2vec_Compositional_Word-Pair_Embeddings_for_Cross-Sentence_Inference, archiveprefix = {arXiv}, eprinttype = {arxiv}, eprint = {1810.08854}, primaryclass = {cs}, title = {Pair2vec: {{Compositional Word}}-{{Pair Embeddings}} for {{Cross}}-{{Sentence Inference}}}, shorttitle = {Pair2vec}, journal = {arXiv:1810.08854 [cs]}, url = {http://arxiv.org/abs/1810.08854}, author = {Joshi, Mandar and Choi, Eunsol and Levy, Omer and Weld, Daniel S. and Zettlemoyer, Luke}, month = oct, year = {2018} } - Kahneman, D. (2013). Thinking, Fast and Slow (1st pbk. ed). New York: Farrar, Straus and Giroux.
@book{Kahneman_2013_Thinking_fast_and_slow, address = {{New York}}, edition = {1st pbk. ed}, title = {Thinking, Fast and Slow}, isbn = {978-0-374-53355-7}, lccn = {BF441 .K238 2013}, publisher = {{Farrar, Straus and Giroux}}, author = {Kahneman, Daniel}, year = {2013} } - Karpinska, M., Li, B., Rogers, A., & Drozd, A. (2018). Subcharacter Information in Japanese Embeddings: When Is It Worth It? Proceedings of the Workshop on the Relevance of Linguistic Structure in Neural Architectures for NLP, 28–37. Melbourne, Australia: Association for Computational Linguistics.
@inproceedings{KarpinskaLiEtAl_2018_Subcharacter_Information_in_Japanese_Embeddings_When_Is_It_Worth_It, address = {{Melbourne, Australia}}, title = {Subcharacter {{Information}} in {{Japanese Embeddings}}: {{When Is It Worth It}}?}, booktitle = {Proceedings of the {{Workshop}} on the {{Relevance}} of {{Linguistic Structure}} in {{Neural Architectures}} for {{NLP}}}, publisher = {{Association for Computational Linguistics}}, url = {http://aclweb.org/anthology/W18-2905}, author = {Karpinska, Marzena and Li, Bofang and Rogers, Anna and Drozd, Aleksandr}, year = {2018}, pages = {28-37} } - Köper, M., Scheible, C., & im Walde, S. S. (2015). Multilingual Reliability and "Semantic" Structure of Continuous Word Spaces. Proceedings of the 11th International Conference on Computational Semantics, 40–45. Association for Computational Linguistics.
@inproceedings{KoperScheibleEtAl_2015_Multilingual_reliability_and_semantic_structure_of_continuous_word_spaces, title = {Multilingual Reliability and "Semantic" Structure of Continuous Word Spaces}, booktitle = {Proceedings of the 11th {{International Conference}} on {{Computational Semantics}}}, publisher = {{Association for Computational Linguistics}}, url = {http://www.aclweb.org/anthology/W15-01\#page=56}, author = {K{\"o}per, Maximilian and Scheible, Christian and {im Walde}, Sabine Schulte}, year = {2015}, pages = {40-45} } - Linzen, T. (2016). Issues in Evaluating Semantic Spaces Using Word Analogies. Proceedings of the First Workshop on Evaluating Vector Space Representations for NLP. https://doi.org/http://dx.doi.org/10.18653/v1/W16-2503
@inproceedings{Linzen_2016_Issues_in_evaluating_semantic_spaces_using_word_analogies, title = {Issues in Evaluating Semantic Spaces Using Word Analogies.}, booktitle = {Proceedings of the {{First Workshop}} on {{Evaluating Vector Space Representations}} for {{NLP}}}, publisher = {{Association for Computational Linguistics}}, doi = {http://dx.doi.org/10.18653/v1/W16-2503}, url = {http://anthology.aclweb.org/W16-2503}, author = {Linzen, Tal}, year = {2016} } - Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. Proceedings of International Conference on Learning Representations (ICLR).
@inproceedings{MikolovChenEtAl_2013_Efficient_estimation_of_word_representations_in_vector_space, title = {Efficient Estimation of Word Representations in Vector Space}, booktitle = {Proceedings of {{International Conference}} on {{Learning Representations}} ({{ICLR}})}, url = {https://arxiv.org/pdf/1301.3781}, author = {Mikolov, Tomas and Chen, Kai and Corrado, Greg and Dean, Jeffrey}, year = {2013} } - Mikolov, T., Yih, W.-tau, & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations. Proceedings of NAACL-HLT 2013, 746–751. Atlanta, Georgia, 9–14 June 2013.
@inproceedings{MikolovYihEtAl_2013_Linguistic_Regularities_in_Continuous_Space_Word_Representations, address = {{Atlanta, Georgia, 9\textendash{}14 June 2013}}, title = {Linguistic {{Regularities}} in {{Continuous Space Word Representations}}.}, booktitle = {Proceedings of {{NAACL}}-{{HLT}} 2013}, url = {https://www.aclweb.org/anthology/N13-1090}, author = {Mikolov, Tomas and Yih, Wen-tau and Zweig, Geoffrey}, year = {2013}, keywords = {_Sasha}, pages = {746--751} } - Nissim, M., van Noord, R., & van der Goot, R. (2019). Fair Is Better than Sensational:Man Is to Doctor as Woman Is to Doctor. ArXiv:1905.09866 [Cs].
@article{NissimvanNoordEtAl_2019_Fair_is_Better_than_SensationalMan_is_to_Doctor_as_Woman_is_to_Doctor, archiveprefix = {arXiv}, eprinttype = {arxiv}, eprint = {1905.09866}, primaryclass = {cs}, title = {Fair Is {{Better}} than {{Sensational}}:{{Man}} Is to {{Doctor}} as {{Woman}} Is to {{Doctor}}}, shorttitle = {Fair Is {{Better}} than {{Sensational}}}, journal = {arXiv:1905.09866 [cs]}, url = {http://arxiv.org/abs/1905.09866}, author = {Nissim, Malvina and {van Noord}, Rik and {van der Goot}, Rob}, month = may, year = {2019} } - Rogers, A., Drozd, A., & Li, B. (2017). The (Too Many) Problems of Analogical Reasoning with Word Vectors. Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (* SEM 2017), 135–148.
@inproceedings{RogersDrozdEtAl_2017_Too_Many_Problems_of_Analogical_Reasoning_with_Word_Vectors, title = {The ({{Too Many}}) {{Problems}} of {{Analogical Reasoning}} with {{Word Vectors}}}, booktitle = {Proceedings of the 6th {{Joint Conference}} on {{Lexical}} and {{Computational Semantics}} (* {{SEM}} 2017)}, url = {http://www.aclweb.org/anthology/S17-1017}, author = {Rogers, Anna and Drozd, Aleksandr and Li, Bofang}, year = {2017}, keywords = {peer-reviewed}, pages = {135--148} } - Schluter, N. (2018). The Word Analogy Testing Caveat. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 242–246. https://doi.org/10.18653/v1/N18-2039
@inproceedings{Schluter_2018_Word_Analogy_Testing_Caveat, title = {The {{Word Analogy Testing Caveat}}}, language = {en-us}, booktitle = {Proceedings of the 2018 {{Conference}} of the {{North American Chapter}} of the {{Association}} for {{Computational Linguistics}}: {{Human Language Technologies}}, {{Volume}} 2 ({{Short Papers}})}, doi = {10.18653/v1/N18-2039}, url = {https://www.aclweb.org/anthology/papers/N/N18/N18-2039/}, author = {Schluter, Natalie}, month = jun, year = {2018}, pages = {242-246} } @inproceedings{ThomasonGordonEtAl_2019_Shifting_Baseline_Single_Modality_Performance_on_Visual_Navigation_QA, title = {Shifting the {{Baseline}}: {{Single Modality Performance}} on {{Visual Navigation}} \& {{QA}}}, shorttitle = {Shifting the {{Baseline}}}, language = {en-us}, booktitle = {Proceedings of the 2019 {{Conference}} of the {{North American Chapter}} of the {{Association}} for {{Computational Linguistics}}: {{Human Language Technologies}}, {{Volume}} 1 ({{Long}} and {{Short Papers}})}, url = {https://www.aclweb.org/anthology/papers/N/N19/N19-1197/}, author = {Thomason, Jesse and Gordon, Daniel and Bisk, Yonatan}, month = jun, year = {2019}, pages = {1977-1983} }- Vine, L. D., Geva, S., & Bruza, P. (2018). Unsupervised Mining of Analogical Frames by Constraint Satisfaction. Proceedings of the Australasian Language Technology Association Workshop 2018, 34–43.
@inproceedings{VineGevaEtAl_2018_Unsupervised_Mining_of_Analogical_Frames_by_Constraint_Satisfaction, title = {Unsupervised {{Mining}} of {{Analogical Frames}} by {{Constraint Satisfaction}}}, language = {en-us}, booktitle = {Proceedings of the {{Australasian Language Technology Association Workshop}} 2018}, url = {https://www.aclweb.org/anthology/papers/U/U18/U18-1004/}, author = {Vine, Lance De and Geva, Shlomo and Bruza, Peter}, month = dec, year = {2018}, pages = {34-43} } - Washio, K., & Kato, T. (2018). Neural Latent Relational Analysis to Capture Lexical Semantic Relations in a Vector Space. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 594–600. Brussels, Belgium: Association for Computational Linguistics.
@inproceedings{WashioKato_2018_Neural_Latent_Relational_Analysis_to_Capture_Lexical_Semantic_Relations_in_a_Vector_Space, address = {{Brussels, Belgium}}, title = {Neural {{Latent Relational Analysis}} to {{Capture Lexical Semantic Relations}} in a {{Vector Space}}}, booktitle = {Proceedings of the 2018 {{Conference}} on {{Empirical Methods}} in {{Natural Language Processing}}}, publisher = {{Association for Computational Linguistics}}, url = {http://aclweb.org/anthology/D18-1058}, author = {Washio, Koki and Kato, Tsuneaki}, year = {2018}, pages = {594-600} } - Yatskar, M. (2019). A Qualitative Comparison of CoQA, SQuAD 2.0 and QuAC. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2318–2323.
@inproceedings{Yatskar_2019_Qualitative_Comparison_of_CoQA_SQuAD_20_and_QuAC, title = {A {{Qualitative Comparison}} of {{CoQA}}, {{SQuAD}} 2.0 and {{QuAC}}}, booktitle = {Proceedings of the 2019 {{Conference}} of the {{North American Chapter}} of the {{Association}} for {{Computational Linguistics}}: {{Human Language Technologies}}, {{Volume}} 1 ({{Long}} and {{Short Papers}})}, author = {Yatskar, Mark}, year = {2019}, pages = {2318--2323}, url = {https://www.aclweb.org/anthology/papers/N/N19/N19-1241/} } - Camacho-Collados, J., Espinosa-Anke, L., & Schockaert, S. (2019). Relational Word Embeddings. ACL 2019.
@article{Camacho-ColladosEspinosa-AnkeEtAl_2019_Relational_Word_Embeddings, archiveprefix = {arXiv}, eprinttype = {arxiv}, eprint = {1906.01373}, title = {Relational {{Word Embeddings}}}, journal = {ACL 2019}, url = {http://arxiv.org/abs/1906.01373}, author = {{Camacho-Collados}, Jose and {Espinosa-Anke}, Luis and Schockaert, Steven}, month = jun, year = {2019} }