
A Sanity Check on ‘Emergent Properties’ in Large Language Models
One of the often-repeated claims about Large Language Models (LLMs), discussed in our ICML’24 position paper, is that they have ‘emergent properties’. Unfortunately, in most cases the speaker/writer does not clarify what they mean by ‘emergence’. But misunderstandings on this issue can have big implications for the research agenda, as well as public policy.
From what I’ve seen in academic papers, there are at least 4 senses in which NLP researchers use this term:
- A property that a model exhibits despite not being explicitly trained for it. E.g. Bommasani et al. (2021, p. 5) refers to few-shot performance of GPT-3 (Brown et al., 2020) as “an emergent property that was neither specifically trained for nor anticipated to arise’”.
- (Opposite to def. 1): a property that the model learned from the training data. E.g. Deshpande et al. (2023, p. 8) discuss emergence as evidence of “the advantages of pre-training’’.
- A property “is emergent if it is not present in smaller models but is present in larger models.’’ (Wei et al., 2022, p. 2).
- A version of def. 3, where what makes emergent properties “intriguing’’ is “their sharpness, transitioning seemingly instantaneously from not present to present, and their unpredictability, appearing at seemingly unforeseeable model scales” (Schaeffer, Miranda, & Koyejo, 2023, p. 1)
For a technical term, this kind of fuzziness is unfortunate. If many people repeat the claim “LLLs have emergent properties” without clarifying what they mean, a reader could infer that there is a broad scientific consensus that this statement is true, according to the reader’s own definition.
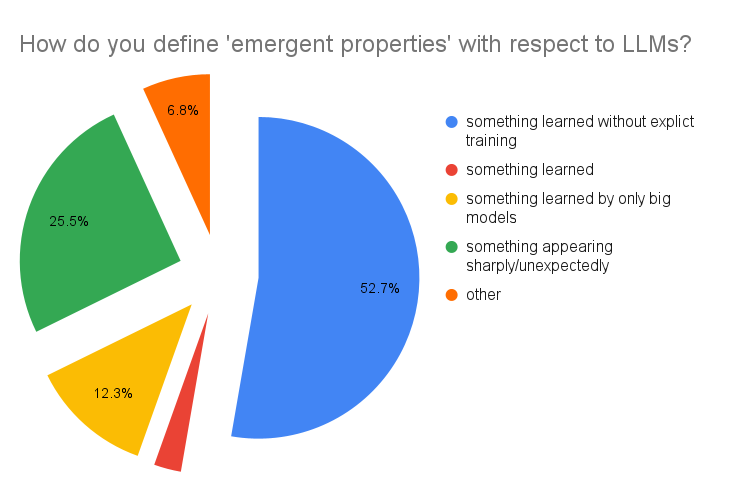
I am writing this post after giving many talks about this in NLP research groups all over the world - Amherst and Georgetown (USA), Cambridge, Cardiff and London (UK), Copenhagen (Denmark), Gothenburg (Sweden), Milan (Italy), Genbench workshop (EMNLP’23 @ Singapore) (thanks to everybody in the audience!). This gave me a chance to poll a lot of NLP researchers about what they thought of emergence. Based on the responses from 220 NLP researchers and PhD students, by far the most popular definition is (1), with (4) being the second most popular.
The idea expressed in definition (1) also often gets invoked in public discourse. For example, you can see it in the claim that Google’s PaLM model ‘knew’ a language it wasn’t trained on (which is almost certainly false). The same idea also provoked the following public exchange between a US senator and Melanie Mitchell (a prominent AI researcher, professor at Santa Fe Institute):
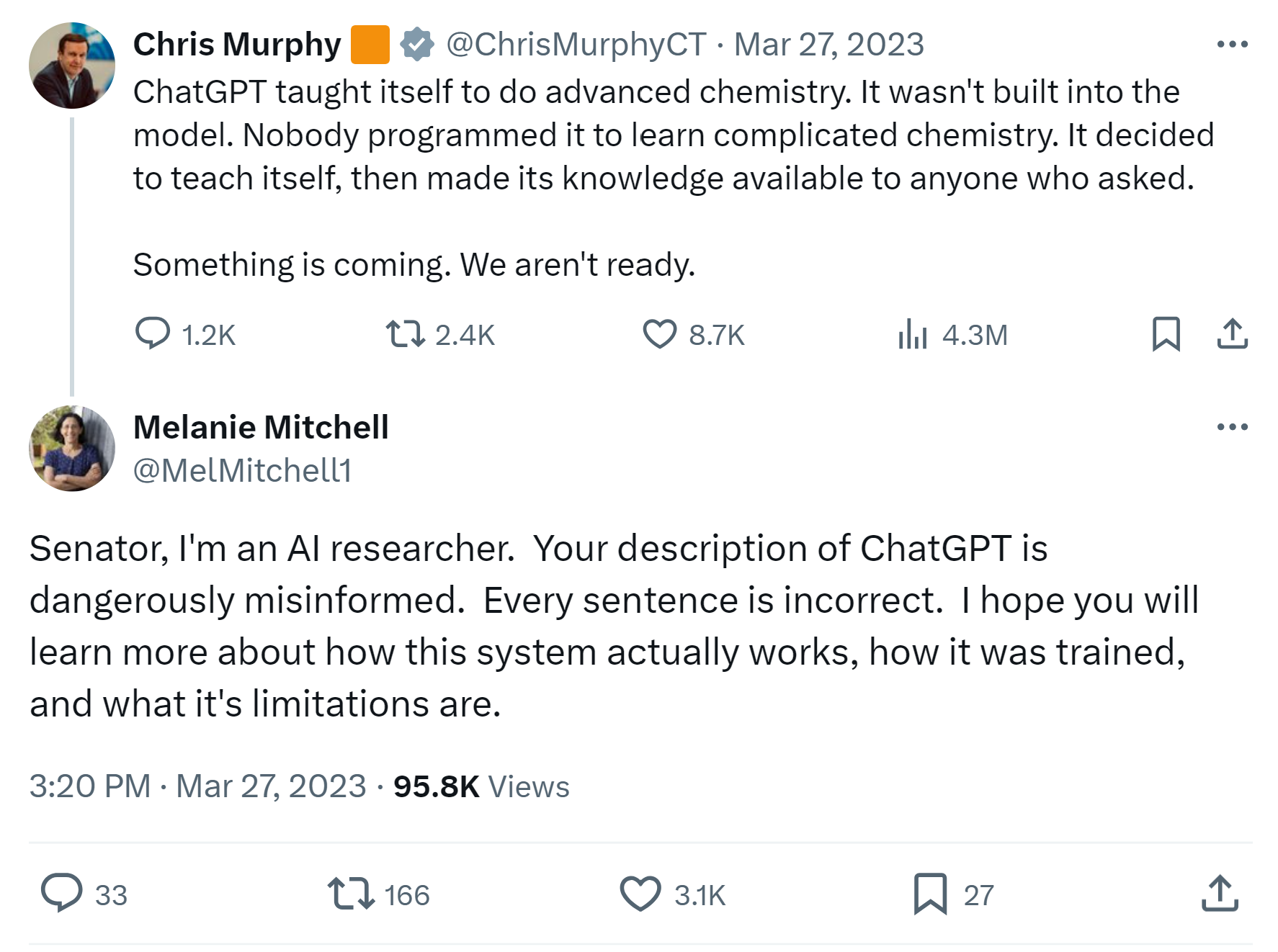
What this exchange shows is the idea of LLM ‘emergent properties’ per definition (1) has implications outside the research world. It contributes to the anxiety about the imminent takeover by super-AGI, to calls for pausing research. It could push the policy-makers in the wrong directions, such as banning open-source research – which would further consolidate resources in the hands of a few big tech labs, and ensure they won’t have much competition. It also creates the impression of LLMs as entities independent on the choices of their developers and deployers – which has huge implications for who is accountable for any harms coming from these models. With such high stakes for the research community and society, shouldn’t we at least make sure that the science is sound?
How much do these notions of ‘emergence’ contribute to the scientific understanding of LLMs?
Much in the above versions of ‘emergence’ in LLMs is still debatable: how much do they actually advance the scientific discussion, with respect to other terms and known principles that are already in use? I would like to stress that this discussion is completely orthogonal to the question of whether LLMs are useful or valuable. Countless models have been and will be practically useful without claims of emergence.
Let us start with definition 2: something that a model learned from the training data. Since this is exactly what a machine learning model is supposed to do, does this version of ‘emergence’ add much to ‘learning’?
For the definition (3) (something that only large models do), the better performance of larger models is to be expected, given basic machine learning principles: the larger model simply has more capacity to learn the patterns in its training data. Hence, this version of ‘emergence’ also does not add much. Unless we expect that the larger models, but not the small ones, do something they weren’t trained for – but then this definition depends on definition (1).
For the definition (4), the phenomenon of sharp change in performance turned out to be attributable to non-continuous evaluation metrics (e.g. for classification tasks like multi-choice question answering), rather than LLMs themselves (Schaeffer, Miranda, & Koyejo, 2023). Furthermore, J. Wei himself acknowledges that the current claims of sharp changes are based on results from models that are only available in relatively few sizes (1B, 7B, 13B, 70B, 150B…), and if we had more results for intermediate model sizes, the increase in performance would likely turn out to be smooth (Wei, 2023).
The unpredictability part of definition (4) was reiterated by J. Wei (Wei, 2023) as follows:
the “emergence” phenomenon is still interesting if there are large differences in predictability: for some problems, performance of large models can easily be extrapolated from performance of models 1000x less in size, whereas for others, even it cannot be extrapolated even from 2x less size.
However, the cited predictability at 1,000x less compute refers to the GPT-4 report (OpenAI, 2023), where the developers knew the target evaluation in advance, and specifically optimized for it. Given that, predictable scaling is hardly surprising theoretically (though still impressive from the engineering point of view). This is in contrast with the unpredictability at 2x less compute for unplanned BIG-Bench evaluation in (Wei et al., 2022). This unpredictability is expected, simply due to the unknown interaction between (a) the presence of training data that is similar to test data, and (b) sufficient model capacity to learn some specific patterns.
Hence, we are left with the definition (1): emergent properties are properties that the model was not explicitly trained for. This can be interpreted in two ways:
- A property is emergent if the model was not exposed to training data for that property.
- A property is emergent even if the model was exposed to the relevant training data -- as long as the model developers were unaware of it.
Per def. 6, it would appear that the research question is actually ‘what data exists on the Web?’ (or in proprietary training datasets of generative AI companies), and we are training LLMs as a very expensive method to answer that question. For example, ChatGPT can generate chess moves that are plausible-looking (but often illegal). This is surprising if we think of ChatGPT as a language model, but not if we know that it is a model trained on a web corpus, because such a corpus would likely include not only texts in a natural language, but also materials like as chess transcripts, ascii art, midi music, programming code etc. The term ‘language model’ is actually a misnomer - they are rather corpus models (Veres, 2022).
Per def. 5, we can prove that some property is emergent only by showing that the model was not exposed to evidence that could have been the basis for the model outputs in the training data. And it cannot be due to lucky sampling in the latent space of the continuous representations. If we are allowed to generate as many samples as we want and cherry-pick, we are eventually going to get some fluent text even from a randomly initialized model – but this should arguably not count as an ‘emergent property’ on definition (5).
For commercial models with undisclosed training data such as ChatGPT, such a proof is out of the question. But even for the “open” LLMs this is only a hypothesis (if not wishful thinking), because so far we are lacking detailed studies (or even a methodology) to consider the exact relation between the amount and kinds of evidence in the training text data for a particular model output. On definition 5, emergent properties are a machine learning equivalent of alchemy – and the bar for postulating that should be quite high.
Especially in the face of evidence to the contrary.
Counter-evidence to ‘emergent properties’ in LLMs
Here are some of the empirical results that make it dubious that LLMs have ‘emergent properties’ by definition (5) (the model was not exposed to training data for that property):
- Phenomenon of prompt sensitivity (Lu, Bartolo, Moore, Riedel, & Stenetorp, 2022; Zhao, Wallace, Feng, Klein, & Singh, 2021): LLMs responding differently to prompts that should be semantically equivalent. If we say that models have an emergent property of answering questions, slightly different ways of posing these questions, and especially different order of few-shot examples, should not matter. The most likely explanation for the prompt sensitivity is that the model responds better to prompts that are more similar to its training data in some way that helps the model.
- Liang et. al evaluate 30 LLMs and conclude that “regurgitation (of copyrighted materials) risk clearly correlates with model accuracy’’ (2022, p. 12). This suggests that models which ‘remember’ more of training data perform better.
- McCoy et al. (McCoy, Yao, Friedman, Hardy, & Griffiths, 2023) show that LLM performance depends on probabilities of output word sequences in web texts.
- Lu et al. (Lu, Bigoulaeva, Sachdeva, Madabushi, & Gurevych, 2023) show that emergent abilities of 18 LLMs can be ascribed mostly to in-context learning. Instruction tuning facilitates in-context learning, but does not seem to have an independent effect.
- For in-context learning itself (first shown in GPT-3 (Brown et al., 2020), and used as the example of ‘emergence’ by Bommasani et al. (2021, pp. 5 % }) , the results of {% cite ChanSantoroEtAl_2022_Data_Distributional_Properties_Drive_Emergent_In-Context_Learning_in_Transformers) suggest that it happens only in Transformers trained on sequences, structurally similar to the sequences in which in-context learning would be tested.
- Liu et al. (Liu et al., 2023) report that ChatGPT and GPT-4 perform better on older compared to newly released benchmarks, suggesting that many evaluation results may be inflated due to data contamination. OpenAI itself went to great lengths in the GPT-3 paper (Brown et al., 2020) showing how difficult it is to mitigate this problem. Since we know nothing about the training data of the latest models, external evaluation results may not be meaningful, and internal reports by companies that sell their models as a commercial service have a clear conflict of interest.
A well-known effort to propose a methodology that would avoid at least the data contamination problem is the ‘sparks of AGI’ study (Bubeck et al., 2023). Using the methodology of newly constructed test cases, checked against public web data, and their perturbations, the authors notably concluded that GPT-4 possesses “a very advanced theory of mind’’. At least two studies have come to the opposite conclusion (Sap, Le Bras, Fried, & Choi, 2022; Shapira et al., 2023). The most likely reason for the failure of this methodology is that while we can check for direct matches on the web, we could still miss some highly similar cases (e.g. the well-known example of unicorn drawn in tikz from that paper could be based on the stackoverflow community drawing other animals in tikz). Furthermore, the commercial LLMs such as GPT-4 could also be trained on data that is not publicly available. In case of OpenAI, hundreds of researchers and other users of GPT-3 have submitted a lot of data though the API, before OpenAI changed their terms of service to not use such data for training by default.
This is not to say that it is absolutely impossible that LLMs could work well out of their training distribution. Some degree of generalization is happening, and the best-case scenario is that it is due to interpolation of patterns that were observed in training data individually, but not together. But at what point we would say that the result is something qualitatively new, what kind of similarity to training data matters, and how we could identify it - these are all still-unresolved research questions.
NLP researchers are actually NOT convinced about LLM emergent properties
As I mentioned, I had a chance to give a talk about this in several NLP research groups. In the very beginning of these talks, before I presented the above discussion, I asked the audience a few questions, including whether they personally believed that LLMs had emergent properties (according to their preferred definition, which, as shown above, was predominantly (1)). I also asked them about their perception of the consensus in the field - what did they think that most other NLP researchers thought about this? For the first question I have answers from 259 researchers and PhD students, and for the second - from 360 (note to self: give people more time to connect to the poll).
The results were striking: while most respondents were sceptical or unsure about LLM emergent properties themselves (only 39% agreed with that statement), 70% thought that most other researchers did believe this.
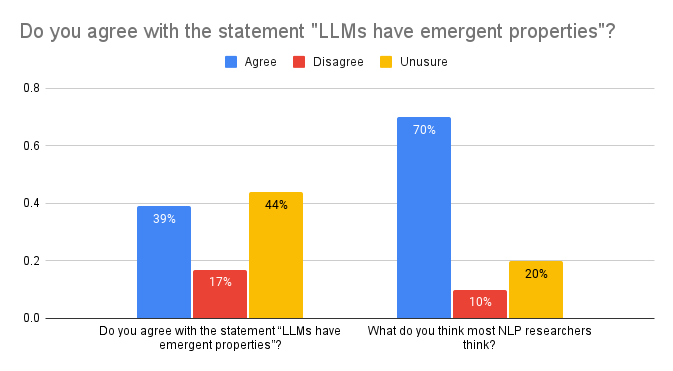
This is in line with several other false sociological beliefs: e.g. most NLP researchers don’t think that NLP leaderboards are particularly meaningful, or that scaling will solve everything, but they do think that other NLP researchers believe that (Michael et al., 2023). In my sample, the idea that LLM have emergent properties is similarly held by a minority of researchers, but it is misperceived to be the majority. And even for that minority the conviction is not very firm. In four of my talks, after presenting the above discussion, I also asked the audience what they thought now. In this sample of 70 responses, 83% of those who originally agreed with the statement “LLMs have emergent properties”, changed their belief to either disagreeing (13.9%) or being unsure (69.4%).
In retrospect, “agree/disagree/unsure” is not the best choice of options for this poll. As scientists, we can hardly ever be 100% sure: as Yann LeCun put it in the Munk debate, we cannot even prove that there is no teapot orbiting Jupiter right now. Our job is not to fall into such distracting rabbit holes, but to formulate and test hypotheses that would advance our understanding of the phenomenon we are studying. For ‘emergence’ in LLMs, I think we are still at the ‘formulation’ stage – since even after all the above work with clarifying ‘emergence’ we still don’t have a research question, for which it is clear how to obtain empirical evidence.
The key unresolved question is what kind of interpolation of existing patterns would even count as something new enough to qualify as an ‘emergent phenomenon’ in the domain of natural language data. This domain is particularly hard, because it mixes different kinds of information (linguistic, social, factual, commonsense), and that information may be present differently (explicit in context, implicit, or requiring reasoning over long contexts). See (Rogers, Gardner, & Augenstein, 2023, pp. sec. 8.2) for a discussion of different skills involved in just the question answering task.
![]() If you will attend ICML or ACL’24, and would like to chat about this, let me know! Also, I am recruiting (PhD and postdoc level).
If you will attend ICML or ACL’24, and would like to chat about this, let me know! Also, I am recruiting (PhD and postdoc level).
This post is based on a part of the ICML 2024 position paper Key Claims in LLM Research Have a Long Tail of Footnotes, by Anna Rogers and Sasha Luccioni. The poll results are not there, but most of the other points can be cited as follows:
@inproceedings{
rogers2024position,
title={Position: Key Claims in {LLM} Research Have a Long Tail of Footnotes},
author={Anna Rogers and Sasha Luccioni},
booktitle={Forty-first International Conference on Machine Learning},
year={2024},
url={https://openreview.net/forum?id=M2cwkGleRL}
}
The paper also discusses what we even mean by ‘large language model’ (as opposed to ‘foundation’ and ‘frontier’ models), and several other often-repeated claims that come with a lot of footnotes: LLMs are robust, LLMs are state-of-the-art, (LLM) scale is all you need, LLMs are general-purpose-technologies.
![]() Acknowledgements:
Acknowledgements:
- my brilliant co-author Sasha Luccioni
- all the anonymous reviewers of the above paper
- Rob van der Goot, Christian Hardmeier, Yacine Jernite, Margaret Mitchell, Dennis Ulmer, who read the early versions of the paper and provided feedback
- Ryan Cotterell, Ishita Dasgupta, Laura Gwilliams, Julia Haas, Anna Ivanova, Tal Linzen, Ben Lipkin, Asad Sayeed for their insights and discussion
- everybody responding to my polls at Cambridge LTL, Cardiff NLP, Center for Language Technology @ Copenhagen University, CLASP, CL@Georgetown, Genbench @ EMNLP23, Milan NLP, QMUL, and UMass Amherst
References
-
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., … Liang, P. (2021). On the Opportunities and Risks of Foundation Models. ArXiv:2108.07258 [Cs].
@article{bommasani2021opportunities, title = {On the {{Opportunities}} and {{Risks}} of {{Foundation Models}}}, author = {Bommasani, Rishi and Hudson, Drew A. and Adeli, Ehsan and Altman, Russ and Arora, Simran and {von Arx}, Sydney and Bernstein, Michael S. and Bohg, Jeannette and Bosselut, Antoine and Brunskill, Emma and Brynjolfsson, Erik and Buch, Shyamal and Card, Dallas and Castellon, Rodrigo and Chatterji, Niladri and Chen, Annie and Creel, Kathleen and Davis, Jared Quincy and Demszky, Dora and Donahue, Chris and Doumbouya, Moussa and Durmus, Esin and Ermon, Stefano and Etchemendy, John and Ethayarajh, Kawin and {Fei-Fei}, Li and Finn, Chelsea and Gale, Trevor and Gillespie, Lauren and Goel, Karan and Goodman, Noah and Grossman, Shelby and Guha, Neel and Hashimoto, Tatsunori and Henderson, Peter and Hewitt, John and Ho, Daniel E. and Hong, Jenny and Hsu, Kyle and Huang, Jing and Icard, Thomas and Jain, Saahil and Jurafsky, Dan and Kalluri, Pratyusha and Karamcheti, Siddharth and Keeling, Geoff and Khani, Fereshte and Khattab, Omar and Koh, Pang Wei and Krass, Mark and Krishna, Ranjay and Kuditipudi, Rohith and Kumar, Ananya and Ladhak, Faisal and Lee, Mina and Lee, Tony and Leskovec, Jure and Levent, Isabelle and Li, Xiang Lisa and Li, Xuechen and Ma, Tengyu and Malik, Ali and Manning, Christopher D. and Mirchandani, Suvir and Mitchell, Eric and Munyikwa, Zanele and Nair, Suraj and Narayan, Avanika and Narayanan, Deepak and Newman, Ben and Nie, Allen and Niebles, Juan Carlos and Nilforoshan, Hamed and Nyarko, Julian and Ogut, Giray and Orr, Laurel and Papadimitriou, Isabel and Park, Joon Sung and Piech, Chris and Portelance, Eva and Potts, Christopher and Raghunathan, Aditi and Reich, Rob and Ren, Hongyu and Rong, Frieda and Roohani, Yusuf and Ruiz, Camilo and Ryan, Jack and R{\'e}, Christopher and Sadigh, Dorsa and Sagawa, Shiori and Santhanam, Keshav and Shih, Andy and Srinivasan, Krishnan and Tamkin, Alex and Taori, Rohan and Thomas, Armin W. and Tram{\`e}r, Florian and Wang, Rose E. and Wang, William and Wu, Bohan and Wu, Jiajun and Wu, Yuhuai and Xie, Sang Michael and Yasunaga, Michihiro and You, Jiaxuan and Zaharia, Matei and Zhang, Michael and Zhang, Tianyi and Zhang, Xikun and Zhang, Yuhui and Zheng, Lucia and Zhou, Kaitlyn and Liang, Percy}, year = {2021}, month = aug, journal = {arXiv:2108.07258 [cs]}, eprint = {2108.07258}, primaryclass = {cs}, url = {http://arxiv.org/abs/2108.07258}, urldate = {2021-08-18}, archiveprefix = {arXiv} } -
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … Amodei, D. (2020). Language Models Are Few-Shot Learners. Advances in Neural Information Processing Systems 33 (NeurIPS 2020).
@inproceedings{BrownMannEtAl_2020_Language_Models_are_Few-Shot_Learners, ids = {BrownMannEtAl_2020_Language_Models_are_Few-Shot_Learnersa}, title = {Language {{Models}} Are {{Few-Shot Learners}}}, booktitle = {Advances in {{Neural Information Processing Systems}} 33 ({{NeurIPS}} 2020)}, author = {Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and {Herbert-Voss}, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and Winter, Clemens and Hesse, Christopher and Chen, Mark and Sigler, Eric and Litwin, Mateusz and Gray, Scott and Chess, Benjamin and Clark, Jack and Berner, Christopher and McCandlish, Sam and Radford, Alec and Sutskever, Ilya and Amodei, Dario}, year = {2020}, month = jun, eprint = {2005.14165}, url = {https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html}, urldate = {2020-06-04}, archiveprefix = {arXiv} } -
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., … Zhang, Y. (2023). Sparks of Artificial General Intelligence: Early Experiments with GPT-4. https://doi.org/10.48550/arXiv.2303.12712
@misc{BubeckChandrasekaranEtAl_2023_Sparks_of_Artificial_General_Intelligence_Early_experiments_with_GPT-4, title = {Sparks of {{Artificial General Intelligence}}: {{Early}} Experiments with {{GPT-4}}}, shorttitle = {Sparks of {{Artificial General Intelligence}}}, author = {Bubeck, S{\'e}bastien and Chandrasekaran, Varun and Eldan, Ronen and Gehrke, Johannes and Horvitz, Eric and Kamar, Ece and Lee, Peter and Lee, Yin Tat and Li, Yuanzhi and Lundberg, Scott and Nori, Harsha and Palangi, Hamid and Ribeiro, Marco Tulio and Zhang, Yi}, year = {2023}, month = apr, number = {arXiv:2303.12712}, eprint = {2303.12712}, primaryclass = {cs}, publisher = {arXiv}, doi = {10.48550/arXiv.2303.12712}, url = {http://arxiv.org/abs/2303.12712}, urldate = {2023-04-29}, archiveprefix = {arXiv} } -
Deshpande, V., Pechi, D., Thatte, S., Lialin, V., & Rumshisky, A. (2023). Honey, I Shrunk the Language: Language Model Behavior at Reduced Scale. Findings of the Association for Computational Linguistics: ACL 2023, 5298–5314. Toronto, Canada: Association for Computational Linguistics.
@inproceedings{deshpande-etal-2023-honey, title = {Honey, {I} Shrunk the Language: Language Model Behavior at Reduced Scale.}, author = {Deshpande, Vijeta and Pechi, Dan and Thatte, Shree and Lialin, Vladislav and Rumshisky, Anna}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2023}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, pages = {5298--5314}, url = {https://aclanthology.org/2023.findings-acl.326} } -
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., … Koreeda, Y. (2022). Holistic Evaluation of Language Models. https://doi.org/10.48550/arXiv.2211.09110
@misc{LiangBommasaniEtAl_2022_Holistic_Evaluation_of_Language_Models, title = {Holistic {{Evaluation}} of {{Language Models}}}, author = {Liang, Percy and Bommasani, Rishi and Lee, Tony and Tsipras, Dimitris and Soylu, Dilara and Yasunaga, Michihiro and Zhang, Yian and Narayanan, Deepak and Wu, Yuhuai and Kumar, Ananya and Newman, Benjamin and Yuan, Binhang and Yan, Bobby and Zhang, Ce and Cosgrove, Christian and Manning, Christopher D. and R{\'e}, Christopher and {Acosta-Navas}, Diana and Hudson, Drew A. and Zelikman, Eric and Durmus, Esin and Ladhak, Faisal and Rong, Frieda and Ren, Hongyu and Yao, Huaxiu and Wang, Jue and Santhanam, Keshav and Orr, Laurel and Zheng, Lucia and Yuksekgonul, Mert and Suzgun, Mirac and Kim, Nathan and Guha, Neel and Chatterji, Niladri and Khattab, Omar and Henderson, Peter and Huang, Qian and Chi, Ryan and Xie, Sang Michael and Santurkar, Shibani and Ganguli, Surya and Hashimoto, Tatsunori and Icard, Thomas and Zhang, Tianyi and Chaudhary, Vishrav and Wang, William and Li, Xuechen and Mai, Yifan and Zhang, Yuhui and Koreeda, Yuta}, year = {2022}, month = nov, number = {arXiv:2211.09110}, eprint = {2211.09110}, primaryclass = {cs}, publisher = {arXiv}, doi = {10.48550/arXiv.2211.09110}, urldate = {2023-07-28}, url = {http://arxiv.org/abs/2211.09110}, archiveprefix = {arXiv}, keywords = {!} } -
Liu, H., Ning, R., Teng, Z., Liu, J., Zhou, Q., & Zhang, Y. (2023). Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4. https://doi.org/10.48550/arXiv.2304.03439
@misc{LiuNingEtAl_2023_Evaluating_Logical_Reasoning_Ability_of_ChatGPT_and_GPT-4, title = {Evaluating the {{Logical Reasoning Ability}} of {{ChatGPT}} and {{GPT-4}}}, author = {Liu, Hanmeng and Ning, Ruoxi and Teng, Zhiyang and Liu, Jian and Zhou, Qiji and Zhang, Yue}, year = {2023}, month = may, number = {arXiv:2304.03439}, eprint = {2304.03439}, primaryclass = {cs}, publisher = {arXiv}, doi = {10.48550/arXiv.2304.03439}, url = {https://arxiv.org/abs/2304.03439}, urldate = {2023-06-21}, archiveprefix = {arXiv} } -
Lu, S., Bigoulaeva, I., Sachdeva, R., Madabushi, H. T., & Gurevych, I. (2023). Are Emergent Abilities in Large Language Models Just In-Context Learning? https://doi.org/10.48550/arXiv.2309.01809
@misc{LuBigoulaevaEtAl_2023_Are_Emergent_Abilities_in_Large_Language_Models_just_In-Context_Learning, title = {Are {{Emergent Abilities}} in {{Large Language Models}} Just {{In-Context Learning}}?}, author = {Lu, Sheng and Bigoulaeva, Irina and Sachdeva, Rachneet and Madabushi, Harish Tayyar and Gurevych, Iryna}, year = {2023}, month = sep, number = {arXiv:2309.01809}, eprint = {2309.01809}, primaryclass = {cs}, publisher = {arXiv}, doi = {10.48550/arXiv.2309.01809}, urldate = {2023-11-22}, url = {https://arxiv.org/abs/2309.01809}, archiveprefix = {arXiv} } -
Lu, Y., Bartolo, M., Moore, A., Riedel, S., & Stenetorp, P. (2022). Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 8086–8098. https://doi.org/10.18653/v1/2022.acl-long.556
@inproceedings{LuBartoloEtAl_2022_Fantastically_Ordered_Prompts_and_Where_to_Find_Them_Overcoming_Few-Shot_Prompt_Order_Sensitivity, title = {Fantastically {{Ordered Prompts}} and {{Where}} to {{Find Them}}: {{Overcoming Few-Shot Prompt Order Sensitivity}}}, shorttitle = {Fantastically {{Ordered Prompts}} and {{Where}} to {{Find Them}}}, booktitle = {Proceedings of the 60th {{Annual Meeting}} of the {{Association}} for {{Computational Linguistics}} ({{Volume}} 1: {{Long Papers}})}, author = {Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus}, year = {2022}, month = may, pages = {8086--8098}, publisher = {Association for Computational Linguistics}, address = {Dublin, Ireland}, doi = {10.18653/v1/2022.acl-long.556}, url = {https://aclanthology.org/2022.acl-long.556}, urldate = {2022-06-15} } -
McCoy, R. T., Yao, S., Friedman, D., Hardy, M., & Griffiths, T. L. (2023). Embers of Autoregression: Understanding Large Language Models Through the Problem They Are Trained to Solve. https://doi.org/10.48550/arXiv.2309.13638
@misc{McCoyYaoEtAl_2023_Embers_of_Autoregression_Understanding_Large_Language_Models_Through_Problem_They_are_Trained_to_Solve, title = {Embers of {{Autoregression}}: {{Understanding Large Language Models Through}} the {{Problem They}} Are {{Trained}} to {{Solve}}}, shorttitle = {Embers of {{Autoregression}}}, author = {McCoy, R. Thomas and Yao, Shunyu and Friedman, Dan and Hardy, Matthew and Griffiths, Thomas L.}, year = {2023}, month = sep, number = {arXiv:2309.13638}, eprint = {2309.13638}, primaryclass = {cs}, publisher = {arXiv}, doi = {10.48550/arXiv.2309.13638}, url = {https://arxiv.org/abs/2309.13638}, urldate = {2024-02-06}, archiveprefix = {arXiv} } -
Michael, J., Holtzman, A., Parrish, A., Mueller, A., Wang, A., Chen, A., … Bowman, S. R. (2023). What Do NLP Researchers Believe? Results of the NLP Community Metasurvey. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 16334–16368. Toronto, Canada: Association for Computational Linguistics.
@inproceedings{MichaelHoltzmanEtAl_2023_What_Do_NLP_Researchers_Believe_Results_of_NLP_Community_Metasurvey, title = {What {{Do}} {{NLP}} {{Researchers Believe}}? {{Results}} of the {{NLP}} {{Community Metasurvey}}}, booktitle = {Proceedings of the 61st {{Annual Meeting}} of the {{Association}} for {{Computational Linguistics}} ({{Volume}} 1: {{Long Papers}})}, author = {Michael, Julian and Holtzman, Ari and Parrish, Alicia and Mueller, Aaron and Wang, Alex and Chen, Angelica and Madaan, Divyam and Nangia, Nikita and Pang, Richard Yuanzhe and Phang, Jason and Bowman, Samuel R.}, year = {2023}, month = jul, pages = {16334--16368}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.acl-long.903/}, address = {Toronto, Canada} } -
OpenAI. (2023). GPT-4 Technical Report. https://doi.org/10.48550/arXiv.2303.08774
@misc{OpenAI_2023_GPT-4_Technical_Report, title = {{{GPT-4 Technical Report}}}, author = {OpenAI}, year = {2023}, month = mar, number = {arXiv:2303.08774}, eprint = {2303.08774}, primaryclass = {cs}, publisher = {arXiv}, doi = {10.48550/arXiv.2303.08774}, url = {http://arxiv.org/abs/2303.08774}, urldate = {2023-06-18}, archiveprefix = {arXiv} } -
Rogers, A., Gardner, M., & Augenstein, I. (2023). QA Dataset Explosion: A Taxonomy of NLP Resources for Question Answering and Reading Comprehension. ACM Computing Surveys, 55(10), 197:1–197:45. https://doi.org/10.1145/3560260
@article{RogersGardnerEtAl_2023_QA_Dataset_Explosion_Taxonomy_of_NLP_Resources_for_Question_Answering_and_Reading_Comprehension, title = {{{QA Dataset Explosion}}: {{A Taxonomy}} of {{NLP Resources}} for {{Question Answering}} and {{Reading Comprehension}}}, shorttitle = {{{QA Dataset Explosion}}}, author = {Rogers, Anna and Gardner, Matt and Augenstein, Isabelle}, year = {2023}, month = feb, journal = {ACM Computing Surveys}, volume = {55}, number = {10}, pages = {197:1--197:45}, issn = {0360-0300}, doi = {10.1145/3560260}, urldate = {2023-05-22} } -
Sap, M., Le Bras, R., Fried, D., & Choi, Y. (2022). Neural Theory-of-Mind? On the Limits of Social Intelligence in Large LMs. In Y. Goldberg, Z. Kozareva, & Y. Zhang (Eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp. 3762–3780). https://doi.org/10.18653/v1/2022.emnlp-main.248
@inproceedings{SapLeBrasEtAl_2022_Neural_Theory-of-Mind_On_Limits_of_Social_Intelligence_in_Large_LMs, title = {Neural {{Theory-of-Mind}}? {{On}} the {{Limits}} of {{Social Intelligence}} in {{Large LMs}}}, shorttitle = {Neural {{Theory-of-Mind}}?}, booktitle = {Proceedings of the 2022 {{Conference}} on {{Empirical Methods}} in {{Natural Language Processing}}}, author = {Sap, Maarten and Le Bras, Ronan and Fried, Daniel and Choi, Yejin}, editor = {Goldberg, Yoav and Kozareva, Zornitsa and Zhang, Yue}, year = {2022}, month = dec, pages = {3762--3780}, publisher = {Association for Computational Linguistics}, address = {Abu Dhabi, United Arab Emirates}, doi = {10.18653/v1/2022.emnlp-main.248}, url = {https://aclanthology.org/2022.emnlp-main.248}, urldate = {2024-07-15} } -
Schaeffer, R., Miranda, B., & Koyejo, S. (2023). Are Emergent Abilities of Large Language Models a Mirage? In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, & S. Levine (Eds.), Advances in Neural Information Processing Systems (Vol. 36, pp. 55565–55581). Curran Associates, Inc.
@inproceedings{schaeffer2023emergent, title = {Are Emergent Abilities of Large Language Models a Mirage?}, booktitle = {Advances in Neural Information Processing Systems}, author = {Schaeffer, Rylan and Miranda, Brando and Koyejo, Sanmi}, editor = {Oh, A. and Naumann, T. and Globerson, A. and Saenko, K. and Hardt, M. and Levine, S.}, year = {2023}, volume = {36}, pages = {55565--55581}, publisher = {Curran Associates, Inc.}, url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/adc98a266f45005c403b8311ca7e8bd7-Paper-Conference.pdf} } -
Shapira, N., Levy, M., Alavi, S. H., Zhou, X., Choi, Y., Goldberg, Y., … Shwartz, V. (2023). Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models. https://doi.org/10.48550/arXiv.2305.14763
@misc{ShapiraLevyEtAl_2023_Clever_Hans_or_Neural_Theory_of_Mind_Stress_Testing_Social_Reasoning_in_Large_Language_Models, title = {Clever {{Hans}} or {{Neural Theory}} of {{Mind}}? {{Stress Testing Social Reasoning}} in {{Large Language Models}}}, shorttitle = {Clever {{Hans}} or {{Neural Theory}} of {{Mind}}?}, author = {Shapira, Natalie and Levy, Mosh and Alavi, Seyed Hossein and Zhou, Xuhui and Choi, Yejin and Goldberg, Yoav and Sap, Maarten and Shwartz, Vered}, year = {2023}, month = may, number = {arXiv:2305.14763}, eprint = {2305.14763}, primaryclass = {cs}, publisher = {arXiv}, doi = {10.48550/arXiv.2305.14763}, url = {https://arxiv.org/abs/2305.14763}, urldate = {2023-11-22}, archiveprefix = {arXiv} } -
Veres, C. (2022). Large Language Models Are Not Models of Natural Language: They Are Corpus Models. IEEE Access, 10, 61970–61979. https://doi.org/10.1109/ACCESS.2022.3182505
@article{Veres_2022_Large_Language_Models_are_Not_Models_of_Natural_Language_They_are_Corpus_Models, title = {Large {{Language Models}} Are {{Not Models}} of {{Natural Language}}: {{They}} Are {{Corpus Models}}}, shorttitle = {Large {{Language Models}} Are {{Not Models}} of {{Natural Language}}}, author = {Veres, Csaba}, year = {2022}, journal = {IEEE Access}, volume = {10}, pages = {61970--61979}, issn = {2169-3536}, url = {https://ieeexplore.ieee.org/abstract/document/9794684}, doi = {10.1109/ACCESS.2022.3182505}, keywords = {c/position,dl/llm,fw/formal,g/public,q/soc/hype} } -
Wei, J. (2023). Common Arguments Regarding Emergent Abilities.
@misc{Wei_2023_Common_arguments_regarding_emergent_abilities, title = {Common Arguments Regarding Emergent Abilities}, author = {Wei, Jason}, year = {2023}, month = may, journal = {Jason Wei's Blog}, url = {https://www.jasonwei.net/blog/common-arguments-regarding-emergent-abilities}, urldate = {2024-05-20}, langid = {american} } -
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., … Fedus, W. (2022). Emergent Abilities of Large Language Models. Transactions on Machine Learning Research.
@article{WeiTayEtAl_2022_Emergent_Abilities_of_Large_Language_Models, title = {Emergent {{Abilities}} of {{Large Language Models}}}, author = {Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and Yogatama, Dani and Bosma, Maarten and Zhou, Denny and Metzler, Donald and Chi, Ed H. and Hashimoto, Tatsunori and Vinyals, Oriol and Liang, Percy and Dean, Jeff and Fedus, William}, year = {2022}, journal = {Transactions on Machine Learning Research}, url = {https://openreview.net/pdf?id=yzkSU5zdwD}, issn = {2835-8856} } -
Zhao, Z., Wallace, E., Feng, S., Klein, D., & Singh, S. (2021). Calibrate Before Use: Improving Few-shot Performance of Language Models. Proceedings of the 38th International Conference on Machine Learning, 12697–12706. PMLR.
@inproceedings{ZhaoWallaceEtAl_2021_Calibrate_Before_Use_Improving_Few-shot_Performance_of_Language_Models, title = {Calibrate {{Before Use}}: {{Improving Few-shot Performance}} of {{Language Models}}}, shorttitle = {Calibrate {{Before Use}}}, booktitle = {Proceedings of the 38th {{International Conference}} on {{Machine Learning}}}, author = {Zhao, Zihao and Wallace, Eric and Feng, Shi and Klein, Dan and Singh, Sameer}, year = {2021}, month = jul, pages = {12697--12706}, publisher = {PMLR}, issn = {2640-3498}, url = {https://proceedings.mlr.press/v139/zhao21c.html}, urldate = {2022-06-24}, langid = {english}, keywords = {!} }